
Les approches du Data Lineage, entre jeu de piste et pérégrinations
La quantité de données produites et enregistrées de par le monde est exponentielle. Par ailleurs, la donnée est devenue de plus en plus complexe et dynamique, rendant difficile sa prise en main de manière propre et efficace. Le fait de comprendre cette donnée, ses origines et ses utilisations constitue un levier car, du fait de son caractère central et de sa haute valeur ajoutée, chaque organisation se doit de maîtriser ce précieux actif. Dans cette optique, le Data Lineage est un outil incontournable.


Qu’est-ce que le data lineage
A la croisée des processus métier, du modèle d’objets métier, du dictionnaire de données et de la cartographie applicative, le data lineage permet d’identifier et de visualiser le parcours et le cycle de vie de la donnée depuis sa source jusqu’à sa restitution ou son usage, avec tous les éléments de ses transformations successives (normalisation, règles de calcul, agrégation, filtrage, etc.).
Le data lineage produit une vision transverse matérialisée sous la forme d’une cartographie des processus de traitement de l’information centrée sur la donnée ; cette cartographie est destinée à de nombreux usages, que ce soit pour la documentation, la conformité réglementaire, la qualité des données ou l’évaluation d’impacts sur l’entreprise. Elle justifie notamment l’exactitude de l’information produite pour la production d’états, d’indicateurs ou de fichiers d’export, et s’impose comme un volet essentiel à la gouvernance des données.
Lineage fonctionnel et lineage technique
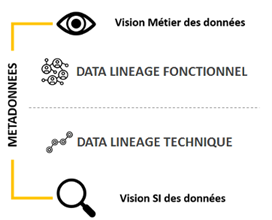
Le lineage fonctionnel permet aux opérationnels et à la gouvernance d’avoir une vision globale du parcours et des transformations de la donnée, sans s’encombrer des détails techniques. Cette vision leur offre le niveau d’information suffisant pour qu’ils puissent s’y appuyer dans leurs prises de décision.
Le lineage technique est une nécessité pour les équipes informatiques qui ont besoin, pour leurs différents projets, de connaitre avec exactitude le parcours et les transformations de la donnée, ainsi que les stockages physiques associés. C’est également un entrant précieux pour constituer le lineage métier et établir ainsi une bonne gouvernance des données.
Les différentes approches dans la constitution d’un data lineage
La constitution de la cartographie des transformations de la donnée au travers de ses parcours dans les systèmes d’information de l’entreprise s’appuie sur de nombreuses approches à évaluer suivant la vision métier ou technique de la démarche à poser, et ce qu’elle soit outillée ou non.
Ces différentes orientations comportent des avantages et des inconvénients que nous allons vous exposer plus en détail.
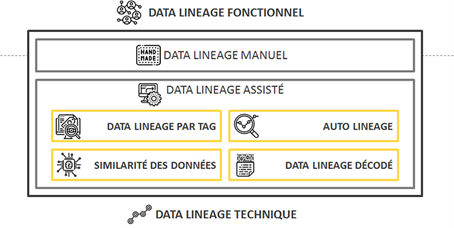
Les lineages manuels
Le lineage manuel fonctionnel
Cette approche consiste à construire le lineage des données en associant et documentant la connaissance métier provenant, par exemple, des responsables applicatifs, des data stewards ou des spécialistes en intégration des données.
Avantages
Cette méthode produit un data lineage prescriptif, c’est-à-dire décrivant comment la donnée devrait circuler, et non quelle est sa circulation actuelle avec ses défauts.
Inconvénients
Parce que cette méthode repose sur une vision idéalisée et humaine, le résultat peut être tronqué, dans le cas d’une méconnaissance de certains jeux de données par exemple, ou encore soulever des contradictions dans le cas d’avis différents suite au recueil de la connaissance métier.
Cela peut engendrer une situation où un lineage est produit, mais est inexploitable pour des scénarios de cas réels. Non seulement il ne sera pas possible de croire aux données, mais également à leurs mouvements. Au final, il sera nécessaire d’avoir un lineage technique de qualité comme socle pour la constitution du lineage métier.
Le lineage manuel technique
Cette méthode constitue le lineage par le recueil et la consolidation des informations techniques (dictionnaire de données, mappings de données, règles de transformation des données, etc.), généralement dans un tableur.
Avantages
Cette démarche permet de débuter le sujet en mode pilote, le temps d’évaluer les différentes actions et leur chronologie, les rôles et responsabilités attendus, de comprendre à grosse maille ce qui se passe dans l’organisation. De surcroit, elle reste également nécessaire pour pister les processus manuels. De fait, l’extraction manuelle d’un jeu de données provenant d’une base et son stockage dans un répertoire du réseau, puis sa réutilisation et sa transformation en local par un métier via l’utilisation d’un tableur, est un exemple de processus manuel encore trop peu souvent décrit dans les organisations.
Inconvénients
C’est certainement la méthode la plus difficile à mettre en œuvre et à faire vivre. Entre le volume de code, sa complexité et sa fréquence de modification, il n’est souvent pas possible de réaliser le data lineage simplement et cela n’ira pas en s’arrangeant, le tout devenant rapidement non maintenable. En effet, en considérant la complexité du code et le besoin de retraduire le code existant, il devient extrêmement chronophage de s’y appuyer et arrivera un moment où la gestion manuelle du lineage technique sera désynchronisée par rapport à la réalité, avec pour conséquence une cartographie de la donnée qui ne sera plus fiable. Le lineage perdant alors tout son sens.
Les lineages assistés
Le lineage par tag
L’idée générale derrière cette approche est que chaque donnée, qui est en mouvement ou transformée, est étiquetée par un moteur de transformation qui piste par la suite l’étiquette sur tout le parcours, de la source à la cible.
Avantages
Le pistage est automatique et il est possible d’utiliser les termes métier afin d’étiqueter les données physiques.
Inconvénients
Cette approche ne fonctionne parfaitement que si le moteur de transformation contrôle chaque mouvement de la donnée. Au-delà de son périmètre, le lineage est rompu. Autre contrainte : le lineage n’est connu que si la logique de transformation est exécutée. Cela signifie que certaines exceptions ou règles d’exécution effectuées annuellement, par exemple, peuvent échapper aux analyses et à la documentation, ce qui est problématique dans une gouvernance des données si certains de ces traitements sont critiques pour l’organisation.
L’auto-lineage
Cette approche nécessite de posséder un environnement tout-en-un qui donne tout ce dont nous avons besoin pour le lineage. Cet environnement tout-en-un peut être obtenu par l’utilisation d’une solution de data virtualisation, big data ou data lake. Il y est possible de définir la logique, de pister le lineage, de gérer les données maîtres et les métadonnées facilement, etc.
Avantages
Ces solutions permettent de mettre en place cette approche, en contrôlant tous les événements pouvant intervenir au sein de l’environnement tels que les mouvements de données et leurs modifications. Il est ainsi donc facile de pister l’origine et la cible d’une donnée ainsi que ses transformations.
Inconvénients
Les limites sont identiques à celles du lineage par tag. Tout ce qui peut survenir en dehors du périmètre ne sera pas pris en compte et restera invisible, provoquant un écart de plus en plus grand au fil du temps par l’apparition de nouveaux besoins et des outils hors périmètre de l’environnement mis en place pour y répondre.
Le lineage par similarité des données
Cette approche élabore le lineage en examinant la donnée et les schémas sans accéder au code. Un profilage est réalisé sur la lecture des métadonnées concernant les tables, les vues, les colonnes, etc. Par la suite, toutes ces informations sont comparées et les associations sont réalisées par similarité. C’est à dire que les tables ou les colonnes ayant des noms similaires, et les colonnes comportant des valeurs de données très similaires sont des exemples de l’approche par similarité. Par conséquent, si de nombreuses similarités sont trouvées entre deux colonnes, elles seront liées et associées dans le diagramme de data lineage. Les éditeurs associent parfois cette approche au machine learning.
Avantages
Cette méthode est indépendante des technologies de programmation car elle n’analyse que la donnée produite sans se préoccuper de la technologie l’ayant générée.
Inconvénients
La détection de données similaires dans une vaste base de données peut prendre beaucoup de temps et de ressources, en particulier à l’initialisation du lineage. Le résultat obtenu ne comportera pas les logiques de transformation de la donnée. L’approche comporte un risque sur les données sensibles ou à caractère personnel à cause du travail effectué sur la donnée en elle-même et non seulement sur les métadonnées. Enfin, cette méthode ne permet pas de détecter les données qui ne sont pas encore produites, dans le cas par exemple de processus effectués ponctuellement de manière manuelle, ou ayant une périodicité de déclenchement particulièrement longue (processus annuel).
Le lineage décodé
Cette approche s’appuie sur les technologies manipulant la donnée telles que les ETL ou ESB par exemple. Les solutions permettant de mettre en œuvre cette approche analysent automatiquement la logique de manipulation de la donnée et la retranscrivent par rétro-documentation afin de construire une compréhension sur la manière dont la donnée évolue. Cela peut être un script SQL, une procédure stockée, un programme Java, ou encore une macro dans un classeur Excel. Cela peut être n’importe quel moyen qui déplace une donnée d’un emplacement à un autre, la transforme et/ou la modifie.
Avantages
Cette méthode met à disposition un lineage technique des données le plus précis, détaillé et complet possible, par l’analyse de chaque logique de manipulation de la donnée.
Inconvénients
Pour couvrir l’étendue des systèmes d’informations d’une entreprise, les analyses de ses logiques nécessitent d’avoir une solution possédant la capacité de comprendre une multitude de langages de programmation et de technologies, ainsi que leurs différentes versions. Cela peut, par ailleurs, être un frein à l’adoption d’une nouvelle technologie si la solution de lineage retenue ne dispose pas du support approprié. Le code évolue au cours du temps, rendant certaines analyses inefficaces sur les mises à jour non prises en compte. La solution doit pouvoir analyser certains cas particuliers tels que :
- Les codes dynamiques utilisant les expressions à la volée basées sur les variables d’environnement, les données contenues dans des tables, et/ou les entrées du programme ;
- Les procédures stockées imbriquées.
Tous les changements d’une donnée ne sont pas générés par un code de programmation. Il arrive exceptionnellement qu’un administrateur de base de données, dans le cas d’une reprise de données en urgence sur le serveur de l’environnement de Production, exécute une séquence de commandes SQL. La solution n’est pas en capacité d’identifier et d’alerter sur les informations inscrites dans le code de la séquence, en contradiction avec la réglementation financière ou RGPD. Autre exemple, dans le cas où deux morceaux de code dans des processus séparés effectuent les mêmes calculs et inscrivent le résultat en base, la donnée sera alors dupliquée : les analyses des logiques ne permettront pas de découvrir le dysfonctionnement car chaque morceau de code fonctionne correctement.
Ce qu’il faut retenir de ces différentes approches
Il n’existe pas de solution parfaite, mais plutôt une combinaison de ces différentes approches à adopter suivant le cadre d’intervention.
- Dans le cadre d’un POC sur un périmètre restreint, une approche manuelle peut être réalisée afin d’identifier les processus à mettre en place, ainsi que les rôles et les responsabilités dédiés.
- Dans la phase de Build, une stratégie de déploiement doit être définie sur les critères de coûts, bénéfices, risques et réglementation. Il s’agit de définir le périmètre organisationnel et les processus sur lesquels un data lineage est à produire. Cette analyse permet de choisir la solution de data lineage et les moyens à mettre en œuvre.
- Débuter par le lineage connu des données en s’appuyant sur la solution choisie. En effet, cette dernière est incontestablement une alliée précieuse pour l’automatisation de la récupération des métadonnées des différentes bases de l’entreprise.
- Par la suite, augmenter le périmètre du lineage sur les données techniques similaires et le rattachement aux termes métier.
- Compléter par une approche manuelle afin d’indiquer les règles du lineage prescriptif sur l’existant, et documenter ce qui n’a pu être automatiquement récupéré avec la solution dédiée.
- Enfin, dans la phase de Run, pour que la démarche reste pérenne, le data lineage technique doit pouvoir être mis à jour de façon continue et dynamique en fonction des évolutions du système d’information et du data lineage fonctionnel cible. Pour ce faire, la construction de ce data lineage doit s’intégrer dans les processus de livraison et de production IT afin de présenter une cartographie data alignée sur le rythme des évolutions du SI.
En conclusion
Ainsi, la mise en place d’un data lineage ne permettra pas de tout obtenir de manière automatique, et ne couvrira pas toutes les données, dès le départ. Cependant, en ciblant les cas d’usages et en augmentant peu à peu le périmètre, des quick-wins permettront d’installer des procédures, des responsabilités, une acculturation à la donnée et, in fine, des retours sur investissement que nous vous décrirons lors d’un prochain article dédié.

Jean-Yves Herpet
Consultant Data et Architecture