
Les bonnes pratiques de la gestion de la qualité des données
L'exemple de BlaBlaCar


Créée en 2006, BlaBlaCar, l’une des licornes françaises les plus historiques, est aujourd’hui leader mondial du marché du covoiturage. L’entreprise a su s’imposer dans les trajets quotidiens et longue distance de millions de personnes à travers le globe. Elle continue d’ailleurs son expansion dans le marché du déplacement notamment à travers la mise en place de lignes de bus.
Bien que leader mondial de son secteur, BlaBlaCar est considérée avant tout comme étant une entreprise pionnière de la French Tech, et dont l’écosystème peut être considéré comme étant une source d’inspiration pour d’autres entreprises. D’autant plus du fait de sa participation à de multiples conférences de manière constante (Big Data & AI Paris, Big Data LDN, Devoxx France, AI in Retail Summit London, etc.).
Afin de comprendre les raisons de ce succès, Pramana a décidé de se pencher sur le volet Data, et plus précisément, la gestion de la Data Quality au sein de BlaBlaCar.
Souhaib Guitouni Engineering Manager de l’équipe Data Ops a accepté de se prêter au jeu, et de répondre à nos questions.

Comment définissez-vous la qualité des données ?
La qualité des données correspond, à mon sens, à la manière avec laquelle la donnée va être reçue par l’utilisateur, c’est-à-dire, la manière avec laquelle elle répond à son besoin.
On s’intéresse ainsi, à la fois au format et au contenu de la donnée.
En fonction des cas, on va analyser des critères tels que la complétude, la vraisemblance (par exemple, la valeur âge doit être positive), la cohérence, etc. Ou encore nous intéresser à d’autres indicateurs, tels que le volume et la fraîcheur des données. Ces derniers nous permettent de nous assurer que les systèmes producteurs de données continuent de fonctionner de manière adéquate.
Par ailleurs, l’architecture que nous choisissons a un impact majeur sur la qualité des données. Et elle doit émerger du besoin final.
Prenons le cas des systèmes à événements : certains besoins autorisent la perte de certains événements ou certaines données tandis qu’ils sont très stricts sur la latence (durée que prendra un événement depuis sa création à son arrivée au consommateur). D’autres peuvent accepter les arrivées tardives, mais n’autorisent pas les pertes, c’est le cas par exemple des applications financières. Une troisième architecture peut être plus flexible sur la latence et la perte de données mais ne pas tolérer les doublons.
Ainsi, pour chaque besoin il y a une architecture correspondante, et pour chaque architecture, il existe des choix d’implémentations techniques différents.
Cette même architecture doit aussi être capable de supporter un éventuel changement des données. C’est surtout vrai pour une startup / scale-up ou le produit évolue régulièrement. Prenons l’exemple du type de trajet : alors qu’historiquement BlaBlaCar ne proposait que des services de covoiturage, aujourd’hui, nous offrons des voyages en bus. Nous devons être capables de prendre en considération ces transformations de la manière la plus lisse possible, sans créer de coutures dans nos processus, ou dans l’expérience utilisateur.
Même si la modification ou l’ajout d’un champ peuvent paraître anodins, nous devons constamment gérer les impacts sur l’architecture globale et les processus pour ne pas créer des goulots d’étranglement mais surtout garantir le respect de la qualité des données et du besoin des utilisateurs, et ce dès le début de nos projets.
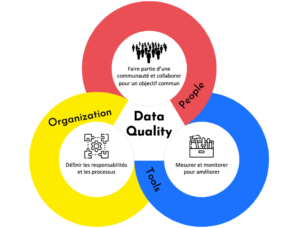
Il ne s’agit pas uniquement d’une préoccupation ponctuelle, mais de toute une organisation : une culture, des processus, une architecture, des outils, et des personnes responsables de la donnée et de sa qualité.

Pouvez-vous donner quelques exemples d’utilisateurs impactés par la qualité des données ?
A vrai dire, tout le monde ! Et pour cause ! Comme mentionné plus haut, Il n’y a pas un utilisateur qui ne soit pas impacté ou responsable de la qualité des données :
- Du comité exécutif au marketing en passant par le produit et la finance. L’ensemble de l’entreprise utilise les données pour pouvoir prendre des décisions informées. Une donnée de bonne qualité permet de prendre la bonne décision. Inversement, une donnée de mauvaise qualité (incorrecte, incomplète ou obsolète) peut avoir des impacts conséquents sur les décisions de l’entreprise (mauvaise décision, décision au mauvais moment, etc.)
- Les Data Analysts et Business Analysts, de par la nature de leur rôle, manipulent constamment les données. Ils vont s’en servir pour toutes sortes de cas : analyser le chiffre d’affaires, les trajets, le marché, le succès des campagnes marketing, l’utilisation d’une nouvelle fonctionnalité du produit, etc. Ils font face à une grande volumétrie de données, et plus le processus va être fluide, l’analyse automatisée et intelligente, plus ils pourront faire avancer celle-ci, déterminer ce qui fonctionne ou non, élaborer des théories plus pertinentes autour des données, et ainsi faciliter la prise de décision.
- Les Data Scientists, quant à eux, vont se servir de toutes sortes de données pour construire des systèmes automatisés de prise de décision, parfois en temps réel, et proposer de construire des services plus innovants.
- Les équipes Back-end vont par exemple avoir besoin de données de qualité pour des projets de transfert de données, de migration, et doivent être capable de comprendre les données pour des besoins de debug. Ils ne peuvent pas se permettre d’envoyer des données « moisies » aux autres équipes ou plateformes.
- Les équipes Front-end, responsables des applications mobiles et du site web, doivent quant à elles garantir un affichage pertinent et l’intégrité des données sur ces plateformes afin de proposer une bonne expérience utilisateur, et fournir un service de qualité.
- Les équipes Back-Office ou le service Client doivent avoir des données de qualité à disposition, et ce pour comprendre les besoins et les comportements des clients et pouvoir répondre de manière adéquate à leurs demandes. Ici la qualité des données peut directement impacter la qualité du service que BlaBlaCar propose.
Quels sont les moyens que vous mettez en place pour faire fonctionner tout ça ?
On peut citer trois catégories principales.
- D’abord, il y a le côté organisationnel et culturel. Chaque équipe a un périmètre bien défini sur lequel elle est responsable. Chez BlaBlaCar, notre credo à ce sujet est : « You build it, you run it. ». Cela veut dire que s’il y a un problème sur un produit du périmètre – la donnée étant considérée comme un produit – c’est l’équipe qui l’a créé qui doit, non seulement, se charger de trouver une solution mais aussi d’être la première à prendre connaissance du problème. Ainsi, ce n’est donc pas à l’équipe consommatrice de corriger les données qu’elle reçoit avant de pouvoir les utiliser. Cela n’empêche en rien qu’il y ait une collaboration entre les équipes pour la résolution des problèmes. La responsabilité, toutefois, doit être claire pour tous. De même, si nous souhaitons faire évoluer le schéma des données, le producteur a la responsabilité de tenir au courant les consommateurs de données avant de valider et mettre en place des évolutions dites “cassantes”.
- Nous avons aussi des outils mis en place :
- Chaque équipe possède ses propres tableaux de bord, et développe ses propres indicateurs et alertes. Ainsi, pour chaque alerte, il y a une liste d’actions, ou un processus clair identifié dans ce que l’on appelle le run book. Aussi, si une nouvelle alerte ou des actions sont identifiées, celles-ci sont documentées et réalisées dans la foulée. De plus, si un incident majeur non connu est identifié, un processus est mis en place pour le gérer avec les équipes responsables.
- Chaque équipe définit aussi des objectifs sur ses indicateurs (Par exemple : ne pas dépasser deux minutes d’indisponibilité par mois), et peut mettre en place des SLOs (Service Level Objectives) pour communiquer le niveau d’exigence assuré. Si l’équipe remarque des problèmes dans l’atteinte de ses objectifs, un plan d’action est mis en place pour pouvoir y pallier.
- Il y a plus d’un an, nous avons commencé à utiliser l’outil Monte Carlo pour construire des “monitors” automatisés sur la qualité de données. L’outil détecte, par exemple, des changements dans la volumétrie, ou encore une baisse de qualité des valeurs d’un champ (changement brusque de distribution, passage à beaucoup de valeurs vides ou nulles, etc.). Il permet aussi aux utilisateurs de créer des règles customisées sur un champ ou une table. Monte Carlo pouvant s’intégrer à des outils comme slack, des alertes peuvent donc être envoyées en cas de détection d’un problème.
- Naturellement, certains contrôles sont mis en place pour prévenir les mauvaises saisies utilisateur. Ces contrôles sont systématiquement définis avec les UX Designers, qui spécifient les exigences d’implémentation sur le site ou l’application, et ce, afin de garantir une expérience utilisateur optimale et ne pas développer des contrôles qui risquent de rebuter ces utilisateurs.
- Nous nous basons aussi sur les feedbacks de nos communautés pour pouvoir nous améliorer en continu. Ces communautés peuvent être celles de nos ambassadeurs et nos utilisateurs ou encore celles des salariés qui vont remonter les problématiques qu’ils détectent à l’équipe Produit, qui de son côté le remonte à l’équipe Engineering. Ces remontées sont systématiquement prises en compte par BlaBlaCar. « Be the member » est notre devise.
Conclusion
Cet échange démontre que, pour BlaBlaCar, la qualité des données est avant tout un moyen de servir comme il faut les utilisateurs et d’orienter les décisions stratégiques de l’entreprise.
Avec cette philosophie en tête, BlaBlaCar a ainsi réussi à cocher toutes les cases des bonnes pratiques à établir pour une gestion durable et pérenne de la qualité des données :
- La prise en compte systématique des besoins des utilisateurs ;
- La gestion de la qualité by design dans les architectures et les projets ;
- La responsabilisation et la collaboration de l’ensemble des parties prenantes pour gérer les données comme un produit à part entière et en garantir sa qualité ;
- Un investissement humain et financier juste – ni trop, ni trop peu – dans des outils, projets, et actions qui permettent de contrôler et remédier la qualité des données ;
- Une amélioration continue des données et des manières de faire ;
- Etc.
Ne sont que quelques exemples de pratiques bien établies qui permettent à l’entreprise de gérer la qualité des données de manière claire et fluide, et ainsi de se concentrer sur le développement d’usages métier innovants ou à haute valeur ajoutée.
Je tiens à remercier Souhaib GUITOUNI pour sa contribution à la rédaction de cet article.

Azza Fehri
Consultante Data